Table of Contents
Introduction to GraphQL
GraphQL is a query language that makes it easy for software developers to request data from a server. It was developed by Facebook and is now used by many large companies around the world.
In simple terms, GraphQL allows developers to specify exactly what data they need, and the server responds with only that data. This means that developers can create more efficient, faster, and more flexible applications, without worrying about over-fetching or under-fetching data.
With GraphQL, developers can easily retrieve and manipulate data from various sources, such as databases, microservices, and APIs, using a single query language. This makes it easier for developers to work with complex systems and build powerful applications.
Why GraphQL
GraphQL was invented as a solution to tackle the drawbacks of REST API. Therefore, let’s see what advantage you have using GraphQL compared to REST API
Advantages ( compared to REST API )
| Advantage | GraphQL | REST API |
|---|---|---|
| Real-time updates are possible with WebSockets or other technologies but require additional setup and infrastructure. | Clients can request only the data they need, reducing overfetching and underfetching. | Clients receive all the data in a predefined structure, even if they only need a small subset of it. |
| Flexible API design | A strongly-typed schema provides a clear contract for the API and allows for a more flexible and modular API design. | The API design is more rigid and typically requires a separate endpoint for each resource or operation. |
| Reduced network requests | Clients can retrieve multiple resources in a single request, reducing the number of network requests needed. | Clients must make separate requests for each resource or operation. |
| Real-time updates | GraphQL subscriptions allow clients to receive real-time updates from the server. | Real-time updates are possible with WebSockets or other technologies, but require additional setup and infrastructure. |
| Tooling and documentation | Real-time updates are possible with WebSockets or other technologies but require additional setup and infrastructure. | REST API documentation and tooling can be inconsistent and fragmented across different libraries and frameworks. |
Disadvantages
Now, let us see if there is any disadvantage to using GraphQL in your next application.
| Disadvantages | Description |
|---|---|
| Steep learning curve | GraphQL can be more complex to learn compared to REST API due to its schema definition and query language. |
| Caching | GraphQL has less support for caching compared to REST API, which can impact performance in certain use cases. |
| Tooling | GraphQL tooling is still developing and evolving, which can make it more difficult to find mature and reliable tools compared to REST API. |
| Security | GraphQL’s flexibility and dynamic nature can make it more difficult to secure compared to REST API, especially when it comes to preventing malicious queries. |
| Cost | Implementing and maintaining a GraphQL server can be more costly compared to REST API, especially for smaller projects. |
What do you need to start a project with GraphQL?
Before we start any applications with GraphQL, let us see what technologies and skills you need to know.
- A server: You will need a server to serve your GraphQL API.
- You can use any web server technology you like, such as
Node.js,Python, Ruby,Java,or .NET
- You can use any web server technology you like, such as
- A database:
- You will need a database to store your data. GraphQL is database agnostic, which means it can work with any database technology you like, such as MongoDB, MySQL, PostgreSQL, or Redis.
- A GraphQL implementation:
- You will need a GraphQL implementation library for your chosen server technology.
- There are many popular GraphQL libraries available, such as Apollo Server, Express GraphQL, and GraphQL Yoga.
- A GraphQL schema:
- You will need to define a GraphQL schema that describes your data model and operations.
- This schema should be written in the GraphQL Schema Definition Language (SDL), which is a simple syntax for defining your API’s types and operations.
- A client:
- You will need a client application to consume your GraphQL API.
- This could be a web application, a mobile application, or any other type of application that can make HTTP requests.
- There are many GraphQL client libraries available, such as Apollo Client, Relay, and urql.
- Knowledge of GraphQL:
- To work with GraphQL, you will need to have a good understanding of how it works and how to write GraphQL queries, mutations, and subscriptions with GraphQL query language
GraphQL Query language
GraphQL Query Language is a powerful and flexible language used to retrieve data from a GraphQL API/ GrapQL server. It allows you to specify the exact data you need by selecting fields on the available types in the schema. With GraphQL Query Language, you can define complex queries with nested fields, pass arguments to filter and sort data, use aliases to rename fields, leverage fragments for reusable query snippets, and employ directives to conditionally include or skip fields. Additionally, variables enable dynamic values in queries, making them adaptable to various scenarios.
Here’s an example of a GraphQL query that retrieves information about a user’s name, email, and the title of their latest 3 posts:
query {
user(id: "123") {
name
email
posts(last: 3) {
edges {
node {
title
}
}
}
}
}This query specifies the fields you want to retrieve for the specified user and their posts, and the server will only return those fields, instead of returning the entire user and posts objects.
Learn more about how to write GraphQL queries in my post: GraphQL Query: How to Talk to the GraphQL Server.
GraphQL project setup
In a typical GraphQL project, the front-end and back-end are separated into distinct layers, with the GraphQL layer acting as a mediator between them.
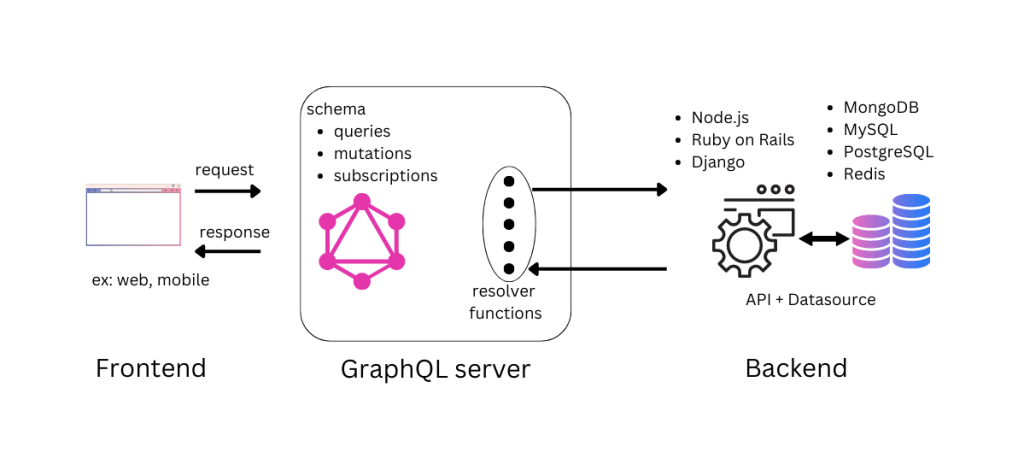
The frontend can be any application that sends HTTP requests and renders responses on a UI. The GraphQL layer( GraphQL server ) sits in between the frontend and backend layers and serves as a bridge between them. It contains schema definitions and resolver functions. While schema definition describes the data available in the API, resolver functions can handle incoming queries, mutations, and subscriptions and delegate them to the appropriate backend service or data source. In return, the backend API fetches data from the datasource and responds to the GrapQL server via resolver functions.
An alternative setup involves integrating the GraphQL server directly into the backend of the system. This setup has the advantage of having efficient communication between the server and backend data sources. However, it also has a downside in terms of scalability. By contrast, when the GraphQL server is implemented as middleware, it allows for greater scalability of the system and more flexibility in choosing and changing backend data sources without affecting the front-end API.
The GraphQL Server: know these concepts before setting up
A GraphQL server is a software application that implements the GraphQL specification and provides an API for clients to interact with. It receives and processes GraphQL queries from clients and returns the requested data in a JSON format.
The server is responsible for resolving the queries and mutations by invoking the appropriate resolver functions. These functions retrieve data from the backend data sources and transform it into the format expected by the GraphQL schema.
The server also handles subscriptions, which allow clients to receive real-time updates as the data changes. The GraphQL server can be implemented in any programming language and can integrate with a wide variety of data sources and middleware.
What is a schema in GraphQL?
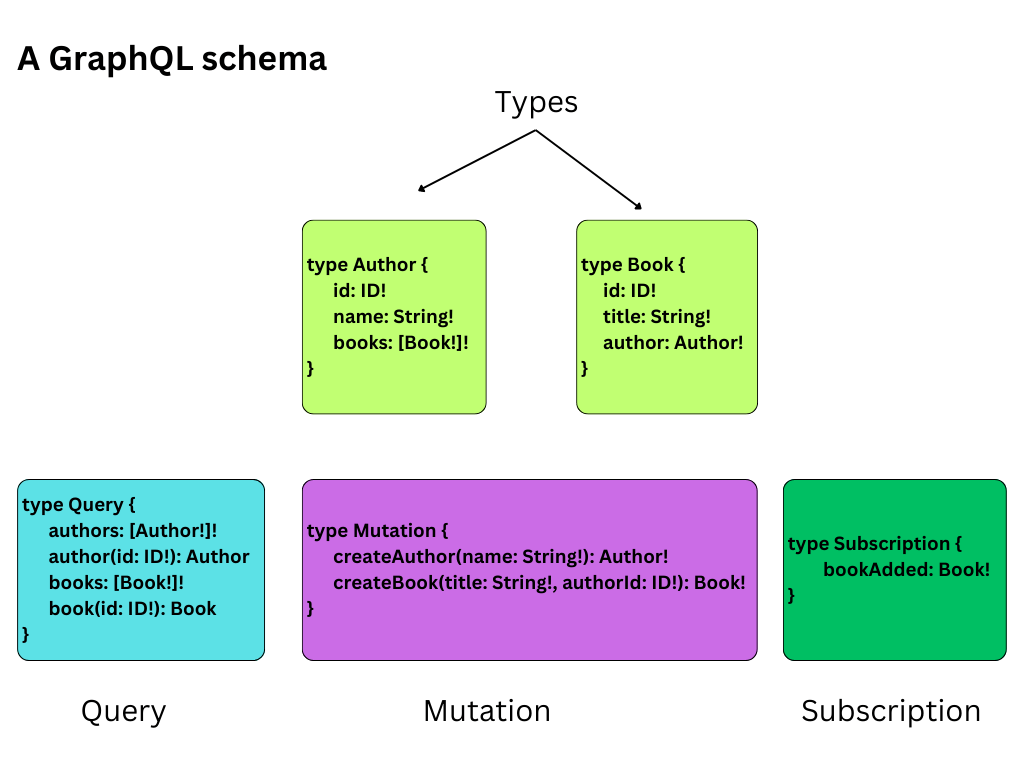
The building block of a GraphQL server is the schema. A schema is a collection of Types that define the data available in an API, the relationships between them, and the operations that can be performed on them
Types define the shape of the data that can be queried or mutated.
A Type (GraphQL type or building blocks of the schema ) contains one or more fields that represent specific pieces of data and their types( primitive data types/scalar types), and it can also include other types as fields to represent relationships between data.
A schema is written in SDL( Schema Definition Langauge ), which is a human-readable syntax that describes the structure of your data and the way your API clients can access it.
type Author {
id: ID!
name: String! # returns a String and non-nullable
books: [Book!]!# A list of Books
}
type Book {
id: ID!
title: String!
author: Author! # returns an Author
}In the above schema, there are two types( GraphQL types) of data, Author, and Book. An Author has an id, a name, and a list of books that they have written. A Book has an id, a title, and an author who wrote the book.
Note the ! after the type of the “id” field in both types. The exclamation mark indicates that the field is non-nullable, meaning it is required and cannot be null.
In addition to the type definitions, you can also define queries, mutations, and subscriptions in a schema.
Learn more about defining schemas and resolvers for queries and mutation in this post.
What are Resolver functions?
Resolver functions are responsible for fetching the data for a single field in your schema. These functions are executed based on queries, mutations, or subscriptions defined in the schema.
Therefore, while this is a common use case for resolvers for fetching data from the backend, they can also be used to perform other actions, such as writing data to a backend data source, invoking external APIs, and performing computations on data before returning it to the client.
You can pass four arguments to a resolver function. All of them are optional.
- parent: The result of the previous resolver call, which is the parent field value.
- args: The arguments provided for the field in the GraphQL query.
- context: A value that is provided to every resolver and holds important information such as the currently logged-in user or database connection.
- info: Information about the execution state of the GraphQL operation, including the field name, field AST, and schema.
let’s take a look a the following schema definition.
type Query {
book(id: ID!): Book
author(id: ID!): Author
}
type Book {
id: ID!
title: String!
author: Author!
}
type Author {
id: ID!
name: String!
books: [Book]!
}for the purpose of this example, we use the following array of objects as our data source
const authors = [
{ id: "1", name: "J.K. Rowling" },
{ id: "2", name: "Stephen King" },
{ id: "3", name: "Haruki Murakami" },
];
const books = [
{ id: "1", title: "Harry Potter and the Philosopher's Stone", authorId: "1" },
{ id: "2", title: "The Shining", authorId: "2" },
{ id: "3", title: "1Q84", authorId: "3" },
];Thus, the resolver functions would be
// Resolvers define how to fetch the types defined in your schema.
// This resolver retrieves books from the "books" array above.
const resolvers = {
// Define resolvers for queries
Query: {
// Return all books
books: () => books,
// Find a book by ID and return it
book: (parent, args) => books.find(book => book.id === args.id),
// Return all authors
authors: () => authors,
// Find an author by ID and return them
author: (parent, args) => authors.find(author => author.id === args.id)
},
// Define resolvers for Author type fields
Author: {
// Return all books written by the author
books: (parent) => books.filter(book => book.authorId === parent.id)
},
// Define resolvers for Book type fields
Book: {
// Return the author of the book
author: (parent) => authors.find(author => author.id === parent.authorId)
}
};In the above code, there are five resolver functions.
books: return all booksbook: find a book by ID and return itauthors: return all authorsauthor: find an author by ID and return themauthor(nested inBooktype) : return the author of the book
Note: These resolvers are for query type. If your schema has mutations or subscriptions, you can have resolvers for them too.
Finally, let’s set up the Apollo GraphQL server
mkdirgraphql_project //Create a project foldermkdirgraphql_project/server //create another folder insidegraphql_project. Name it asservercd graphql_project/server//move into the “server” foldernpm init//initialize the node projectnpm install @apollo/server graphql//install necessary packagesgraphql: The library that implements the core GraphQL parsing and execution algorithms.@apollo/server: The Apollo GraphQL server
- Now, open your project folder in a text editor
- We will be using ES Modules in setting up the project. so, you need to modify the
package.json file.- add
"type":"module"topackage.jsonfile
- add
- create an index.js file in the server folder, and add the “import” statements
import { ApolloServer } from '@apollo/server';
import { startStandaloneServer } from '@apollo/server/standalone'; 9. Add the following schema to index.js file
import { ApolloServer } from '@apollo/server';
import { startStandaloneServer } from '@apollo/server/standalone';
// A schema is a collection of type definitions (hence "typeDefs")
// that together define the "shape" of queries that are executed against
// your data.
const typeDefs = `type Author {
id: ID!
name: String! # returns a String and non-nullable
books: [Book!]!# A list of Books
}
type Book {
id: ID!
title: String!
author: Author! # returns an Author
}
type Query {
authors: [Author!]!
author(id: ID!): Author!
books: [Book!]!
book(id: ID!): Book!
}`10. Now, add the sample data set to index.js. please note this is for the purpose of this example. Apollo server can fetch data from other data sources such as databases, REST API, or JSON files.
//sample dataset. We will fetch data from these array of objects
const authors = [
{ id: "1", name: "J.K. Rowling" },
{ id: "2", name: "Stephen King" },
{ id: "3", name: "Haruki Murakami" },
];
const books = [
{ id: "1", title: "Harry Potter and the Philosopher's Stone", authorId: "1" },
{ id: "2", title: "The Shining", authorId: "2" },
{ id: "3", title: "1Q84", authorId: "3" },
];11. Add the following resolver functions to index.js
// Resolvers define how to fetch the types defined in your schema.
const resolvers = {
// Define resolvers for queries
Query: {
// Return all books
books: () => books,
// Find a book by ID and return it
book: (parent, args) => books.find(book => book.id === args.id),
// Return all authors
authors: () => authors,
// Find an author by ID and return them
author: (parent, args) => authors.find(author => author.id === args.id)
},
// Define resolvers for Author type fields
Author: {
// Return all books written by the author
books: (parent) => books.filter(book => book.authorId === parent.id)
},
// Define resolvers for Book type fields
Book: {
// Return the author of the book
author: (parent) => authors.find(author => author.id === parent.authorId)
}
};12. Last step is to configure the Apollo server and start it.
// The ApolloServer constructor takes two parameters: the schema and the resolvers you created
const server = new ApolloServer({
typeDefs,
resolvers,
});
// Passing an ApolloServer instance to the `startStandaloneServer` function.
// start the server at port 4000 on localhost
const { url } = await startStandaloneServer(server, {
listen: { port: 4000 },
});
console.log(`Server starts at: ${url}`);12. start your server at `http://localhost:4000, and run some test queries. In this video, I am using the GraphQL query language to fetch data from the GraphQL server.
Last thoughts
In this introduction to GraphQL, we covered the reasons why GraphQL is useful and its advantages over traditional REST APIs. We also discussed the steps required to set up a GraphQL project, including the important concepts of schema and resolvers. Before delving into more advanced GraphQL topics, it’s essential to understand how to create a GraphQL server, which we explained in detail. Now that you have the knowledge to run a GraphQL server on your local machine, you can start practicing by writing simple queries and becoming familiar with the GraphQL syntax in SDL.
You can learn how to define schemas for queries and mutations in my next GraphQL post in detail.
